Chapter sixteen
The two brains

Vervet monkey. A synesthetic monkey brain could elicit in the brains of nearby monkeys, with a simple vocalized sound like a snort or a hoot, the remembered image and/or scent of a specific predator — a snake, an eagle, or a leopard. This type of vocal warning signal works more like television than talking. The Vervets’ synesthetic communication system would antedate human language by about 19 million years. It is not really a language, but it offers a template against which a verbal language could be assembled.
Two different brains, two different development programs
A possibility begins to surface. Imagine two distinct brains, one archaic and one modern. The two brains develop in two different evolutionary settings. The archaic human visual brain is pre-verbal and it was perfected, before language dominated thought — for thinking in pictures. The “verbal” human brain is modern, perfected by and in parallel with the development of human language. This seems to have required the suppression of ancestral visual thinking. Instances of modern humans who exhibit archaic brain skills are, at least in part, atavisms.
It is possible language emerged less than 100,000 years ago, and some authors suggest just 50,000 years ago. If so we are walking around with both brains encoded in our chromosomes, archaic and modern, along with two distinctly different brain building programs. In most children the modern, talking-brain program runs to completion without incident and the archaic picture-brain program is much abbreviated or perhaps never launched. Occasionally, however, both brain building programs are triggered, and they fight for control. The outcomes of the conflict, in this hypothesis, could include autism, genius, photographic memory and synesthesia.
It almost appears that the hopelessly unfashionable and vulgarized 20th century notion of a dual brain — Right and Left, Visual and Verbal — has popped up once again. But here are some differences.
The familiar left and right brains were created, a few decades ago, with a knife slice through the corpus callosum. The visual and verbal brains we are now sketching were created in two different evolutionary epochs and were thus shaped by two different types of evolutionary pressure. These two brains, one verbal and one visual, occupy the same space inside the skull. Perhaps they may compete for this space, perhaps they are amalgamated within it. In any event, these two brains are not neatly mapped into right and left hemispheres, as were those in the prevailing model of the 1970s and 1980s.
The brain learns to listen
The eye evolved long before the ear. It is thought that the ear evolved in amphibians from the lateral line organ of fish, which uses hair cells. But there are divergent views that suggest the ear evolved independently in amphibians. One suggestion is that the most rudimentary ear was a supernumerary eye sensitive in the infrared (heat) range, since hair cells have this sensitivity.
In any event there are many familiar touchstones from the visual nervous system in the auditory nervous system, including ribbon synapses. One can juxtapose an eye and an ear and point out the analogous components. For example, the retina is broadly analogous to the organ of Corti. The optic nerve is analogous to the auditory nerve. The photoreceptors are broadly analogous to hair cells.
But what about the tapering basilar membrane, stretched inside of the cochlea? What part of the visual system, if any, does this component resemble?
The basilar membrane, adopted from Introduction to Cochlear Mechanics.
The basilar membrane is functionally analogous to the lens of the eye — which produces, at its back focal plane, a Fourier pattern.

Both structures, the lens and the membrane, are capable of shifting incoming signals — images and sounds, respectively — into the frequency domain.
Let’s emphasize this: On the front end of two different sensory systems, vision and hearing, are these two very different structures, the back focal plane of the lens and the basilar membrane. Yet they both work toward the same end product — a Fourier pattern. One should read this as a strong clue that the brain is using Fourier filtering and processing.
The concept of the brain as a Fourier processor glides in and out of fashion and is a recurring theme in this book. In biology it is largely a forgotten promise but AI researchers are actively experimenting with Fourier processing in machine vision and in speech recognition systems. The idea the brain could be modeled as a Fourier machine has a half-century history. It was originally suggested by Pieter Jacobus van Heerden in April, 1963, in two back-to-back papers in the Journal of Applied Optics.
The eye’s lens produces a Fourier pattern automatically at the speed of light. This is simply an inherent property of the lens — it is effortless. To arrive at a Fourier distribution the ear relies on a simple but highly mechanized sorting process, as shown here:
The basilar membrane of the Organ of Corti with its associated neural circuitry is a machine for frequency analysis.
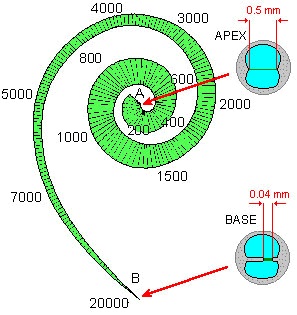
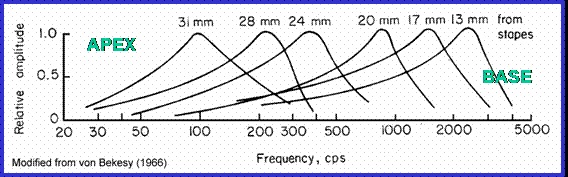
This inspired animation (© 1997 Howard Hughes Medical Institute) unrolls the basilar membrane to show that it is narrow at one end (the base) and broad at the other (the apex, nearest our point of view). Turn on the sound. The animation shows how the membrane responds to Bach’s most famous Toccata. Notice that high frequency tones resonate strongly at the narrow, base end of the membrane, and low frequency sounds resonate strongly at the apex, or broad end. Thus, the component frequencies of the incoming sound waves can be physically separated and separately measured for intensity. Frequency peaks can be mapped against the length of the membrane, as shown here.
Movements of the basilar membrane are detected by 16,000 hair cells positioned along its length. Their responses trigger firing in nerve fibers that communicate information to the brain.
The wedge shape of the membrane establishes a cochlear place code. The membrane is a yardstick. If a particular clump of hair cells is detecting a vigorous movement of the membrane at a point along its length, it means the incoming tone is resonant at a specific frequency. A neuron mounted at that point is thus a frequency specific reporter.
The basilar membrane is a long, wedge shaped tabletop for sorting incoming sound into its constituent frequencies, using resonance length as a criterion.
The animation can be reviewed here along with a helpful voice over commentary by A. James Hudspeth at Rockefeller.
On the Hudspeth Lab web site it is remarked that the animation exaggerates the process in order to make clear what is happening. The actual movements of the membrane are much faster than shown in the animation, since the membrane oscillates at the frequencies of the tones — hundreds or thousands of cycles per second. The amplitudes of the movements are also far smaller, of atomic dimensions.
How fast can this sensor operate? How fast can the brain’s auditory processing system absorb and analyze incoming sounds? The near realtime performance of the brain in transforming streams of words into meaning suggests the system is very fast indeed — probably much faster than the textbook neuron allows. A multichannel system seems called for, using either some form of parallel processing or the incremental analog neuron suggested in Chapter 2.
Speech recognition
It seems a reasonable guess that the visual memory system that originally evolved from the eye was copied and adapted, in the brain, to form an auditory memory. But this is not quite enough. In modern humans, we require a memory for words. And something more. Dogs and cats know a few words. But they do not use words to communicate. And they don’t think in words.
Language is often cited as the turning point in human progress, and it must have been a fairly recent shift or tickover point in evolutionary history. There occurred undoubtedly a parallel or anticipatory change in the brain. Maybe this required the further modification (or perhaps to some degree expropriation) of visual memory machinery in order to create, in effect, a word processor.
What the Denisovan girl’s genes might be able to show us, one day, is a point along this evolutionary continuum between thinking in pictures — and thinking in words. It seems inescapable that these two processes are competitive.
The early mammalian brain was a visual thinking machine. A mixed and somewhat conflicted visual and verbal thinking machine gradually emerged from it in humans. Perhaps the visual memory for objects was modified to create a memory for sounds and then words. It might be that edge detection in the eye was a technical prototype for the detection, by human beings, of the edges between their words.
In the Fourier visual memory model we have discussed in earlier chapters, there is no great distance between the memory process and the thought process. But from a data processing point of view, words are ever so much smaller than pictures. An image of the sun is a hog for computing resources compared with the tiny one syllable word, “sun.”
Thinking in words is probably a more compact process than thinking in pictures. The payoff and evolutionary advantage for verbal reasoning is quicker thinking and a form of communication that can be whispered or shouted.
A problem we are suggesting here is that verbal reasoning may somehow step on or strongly inhibit the much older and probably more highly evolved ability to think in pictures.
One explanation might be that the verbal memory and reasoning machinery was improvised in humans, maybe 50,000 years ago or less, by simply taking over for word processing some core component of the visual memory machine. The visual memory still works in talkative humans, more or less, but it is no longer up to the task of “thinking in pictures.”
The essential first step
Speech recognition in computers shows us what a logical computer designer might do in order to create, starting from scratch, a receiver and transmitter for words. It is a hellishly complicated business, involving cutting the incoming words into phonemes, and then using statistical techniques and context and brute force computing power to achieve rapid word recognition.
But the very first step, so obvious that it almost goes unmentioned, is digitizing. An analog audio signal is fed into an A-to-D converter in order to give the computer a digital data stream it can work with.
We might imagine that if the human brain’s visual memory computer was modified by evolution to recognize and reason in words — nature also had to take an “obvous first step”.
It would not be digitizing, since the brain is an analog computer.
 To make use of the brain’s visual reasoning machinery, the incoming sound signals from the organs of Corti would have to be transformed into patterns that look like those produced by the retinas. This means quite specifically that sound signals would have to be converted and portrayed as images in the frequency domain.
To make use of the brain’s visual reasoning machinery, the incoming sound signals from the organs of Corti would have to be transformed into patterns that look like those produced by the retinas. This means quite specifically that sound signals would have to be converted and portrayed as images in the frequency domain.
In the eye, the Fourier conversion is accomplished by a lens. In the ear the basilar membrane of the Organ of Corti, with its associated neural circuitry, is a machine for distributing incoming sounds into the frequency domain.
This critical conversion step is the original, visual brain’s equivalent of a digital computer’s A-to-D converter. Maybe we should call it an A-to-F converter, where F=Fourier pattern.
Vision is the senior sense. The much newer ability to hear probably mimiced the pattern established by its older sibling. Incoming sound must be depicted as a Fourier pattern in order to gain access to a neuronal memory machine originally evolved for thinking in pictures.

We can guess that the machinery already in place for image recognition was ported over — tinkered into place — and made to work. This suggests speech recognition in the brain happens in the frequency domain. In effect, sounds become images in the frequency domain, that is, images of Fourier patterns. These are tested against and ultimately matched to sonic Fourier images cycled out of memory. Multiple comparators we have styled as Fourier flashlights or projectors are set up and constantly running short film strips — dictionaries this time — in parallel. The system is massively parallel, multitasking and, as in the visual system, memory anticipates reality. Incoming words are recognized almost instantaneously.
In consequence, a machine that was once finely tuned to process pictorial information surrendered a chunk of its picture handling capacity to the processing of Fourier patterns that depict words. One wonders whether there might be a dynamic allocation between visual and verbal reasoning spaces, depending on whether the brain is caught up in an animated conversation or silently painting a picture.
Note that we have given ourselves a hint, here, at the nature of synesthesia –and a further hint at the reason for the curious linkage between synesthesia and memory. This brings us back to the story of the Russian mnemonist, Solomon Shereshevsky. Here is an excerpt from the New Yorker‘s review of Luria’s book, The Mind of a Mnemonist:
A distinguished Soviet psychologist’s study…[of a] young man who was discovered to have a literally limitless memory and eventually became a professional mnemonist. Experiments and interviews over the years showed that his memory was based on synesthesia (turning sounds into vivid visual imagery), that he could forget anything only by an act of will, that he solved problems in a peculiar crablike fashion that worked, and that he was handicapped intellectually because he could not make discriminations, and because every abstraction and idea immediately dissolved into an image for him.
In the model of memory we have suggested here, at least two senses, sight and hearing, are sharing a common memory and recall system. To the memory, there is little technical difference between incoming visual images and remembered sounds or words. They are all Fourier patterns. In a rudimentary or slightly out of kilter system, an incoming visual might be read as a sound, or an incoming word might immediately “dissolve into an image.” One might easily find oneself “hearing colors”.
A science fiction story about synesthesia
How did an ape learn to talk?

In this model of the brain two sensory systems, vision and hearing, produce and process similar patterns — Fourier patterns. A Fourier pattern arriving from the ear looks, to the brain, very like a Fourier pattern captured by the retina. We have suggested that if Fourier patterns arriving from these two distinct sensory systems were confounded in the brain, the effect might be synesthesia. Hearing colors, for example. Similarly the ability to “think in pictures” recounted by Temple Grandin, and the memory techniques described by Solomon Shereshevsky, depend upon an instant conversion of incoming sounds — words — into images.
We can go further with this model by making up a story. Suppose an ape, our ancestor, had a missing, faulty, leaky or intermittent partition between his brain’s processors for vision and hearing. As a result the incoming signals from the ear and the eye might co-exist, badly sorted, with no partition between them.
This goes beyond accounts of contemporary synesthesia in modern human brains. The story calls for a pre-historic brain with the gates left open, constantly receptive to Fourier patterns received from two different sources, the eye and the ear.
Suppose our ancestor, sitting by himself in a tree one night, started playing with his synesthesia by deliberately making lots of different vocal noises and noticing the mental pictures and colors they could induce inside his head.
Maybe he got quite good at this game, so that by experimentally cooing or whining in a particular way he could forcibly regenerate in his head a specific image. A remembered image of a bear, let’s say. With a different sound he might induce the recall of the image of a bird.
In our model of a modern human brain, images from memory, once recalled, surface “from out of nowhere.” The energetic Fourier processing that produces these visual memories is invisible, offstage. In an ancestral primate brain, however, maybe some Fourier processing was visible and impinged upon the animal’s conscious reality. Fourier patterns induced by sounds might be read from a Fourier plane in the brain. We have modeled this component as a retina of memory. Perhaps it was shared by Fourier patterns of both visual and auditory origin. In addition, Fourier patterns created by the eye’s lens might have been read from the retinal Fourier plane as colors and fluid patterns and textures, again impinging on the animal’s everyday conscious reality.
In the end, however, the remembered bear in the ape’s mind would be spatial — very like our modern, quite literal image of a bear.
This artistic process, using vocalized sounds to elicit remembered images, depends in the model upon the brain reading input signals from the ear as though they had arrived from the eye. It also depends on getting the sounds about right. Not perfect. A partial Fourier pattern generated from a sound signal should be sufficient to elicit from memory a whole image of a bear, or at least that of a huge animal standing on its hind legs. (A van Heerden type memory will locate the memorized images that are most similar to the image represented by the Fourier pattern presented for comparison by the input organ. Exact matches are not required.)
An interesting way to entertain oneself in a tree, yes. Sing a little song and watch a film strip of remembered images from the past.
But imagine the new power to communicate this discovered skill gave to this synesthetic ape. The learned whistle-whine-warble that induced in his own head the image of a bear — would also have the power to induce the image of a bear inside the head of every family member and cousin within earshot.
The tribal survival value of this new skill, which is a first prototype of a language, is substantial.
Note that the technique works more like television than talking. It uses vocalized sound waves to transmit across the space from one animal brain to another… the image of some object in the world.
Words do this but words, as we understand the term, came later.
What carries the message here is a crude replica of a Fourier pattern originally made upon the retina by a living bear. The replica is constructed in the brain by experimenting with sounds, vocalizing, until a bear suddenly reappears in the mind’s eye. The image of the bear is induced — coaxed out of memory — by a certain vocal sound. The sound and the process are repeatable. Each time the sound is vocalized, the bear reappears. Anyone else hearing this particular sound should also see (that is, remember) a bear in his or her mind’s eye.
So in this story at least, that’s how and why the first word for “bear” was spoken or sung or hummed or chuttered by an ape. And that’s how words came to be associated in the brain with visual images recalled from the memory’s catalog of visual images. Quite automatically.
From this point it ought to be a downhill run to language but maybe it isn’t.
In 1980 it was confirmed by Dorothy Cheney and Robert Seyfarth that vervet monkeys use alarm calls that do much more that raise an alarm. These calls seem to communicate the specific nature of an imminent danger — that from a leopard, snake or eagle. It would be easy to guess the monkeys are using monkey words, nouns in fact, for leopards, snakes and eagles in order to denote these predators. This idea repels students of language. A thick, famous book about human language, almost as a first step, pushes aside the notion a vervet monkey could use words in the way humans use words.
My guess would be that these monkeys are using specific alarm call sounds to elicit, in other monkeys, remembered images of leopards, snakes and eagles. These sounds are not words like our words. They are protowords that cue visual memory.
If this is how Vervets communicate, then maybe a synesthetic common ancestor invented this system more than 20 million years ago. It is as plausible to guess it was invented independently in several species. In either case we should ask why we progressed from warning cries to human language and why these monkeys did not.
What would constitute progress? A next step would be to skip the re-imaging process and directly link a sound — probably a simplified sound — with a known object in the world. This shortcut produces real words that elicit stored “meanings” shared by the community. It ultimately produces a language that is, perforce, unique to a particular community of archaic humans. It is no longer a universally understandable, pictorial mode of communication.
It proved much faster to use real words rather than protowords that elicit stored pictures. This shortcut step probably required the suppression of synesthesia. Walls gradually went up between the senses. Walls also grew up between human communities that could not comprehend each others’ unique spoken languages.
If a story like this were true and who knows — then we are all descended of synesthetes. Synesthesia is at the root of the unique success, through language, of the human ape. And modern synesthesia is an atavism.
There is a sidebar hypothesis. This story suggests an evolutionary role for music. Perhaps melodies were the tooling we humans used to construct a language. Music could be used to elicit and transmit to another human brain a series of pictures, a film strip in effect, by means of an ordered sequence of vocalized sounds. In this hypothesis the sound track does not merely accompany the movie. The sound track creates the movie.
The notion that synesthesia enabled human language fell out of the Fourier pattern matching model of the brain’s memory. I thought at first it might be an original idea. However, a search on “synesthesia and ape” immediately turned up the thinking of Terrence McKenna (1946-2000) who attributed the invention of language to a “stoned ape.” McKenna’s ape induced synesthesia by ingesting psilocybin. This “led to the development of spoken language: the ability to form pictures in another person’s mind through the use of vocal sounds.”
The hallucinogenic drug doesn’t seem necessary. The idea that language follows from synesthesia makes sense without it. But that’s just a quibble. Perhaps a quarter of a century ago, McKenna thought his way all the way through to the origin of words.
Photographic memory
From a careful observation, it is now clear that the capacity of the visual memory for object details is massive. The verbal thought process appears fast and compact. Verbal memory could be relatively small and limited by its small capacity.
If we were to accept anecdotes about photographic memory, the visual memory is not only huge but also indelible.
Indelible?
To fall back on an analogy to computers — a sufficiently huge memory could appear to be indelible because it is never necessary to over-write it, nor to shuttle its contents to and from some deeper memory store. If a memory has great capacity it can be permanent.
If somehow the verbal memory could gain access to the vast capacity of the pictorial memory, perhaps one might achieve a “limitless” memory capacity like that of Luria’s patient, the amazing mnemonist. This tack might give us a way to think about the genius of Winston Churchill. He was a painter, a pictorial thinker and visual strategist but was nevertheless a walking Oxford Dictionary of the English Language.

As late in evolutionary history as the Cro-Magnons, we know that some modern humans were still strongly pictorial in their thinking. This painting was dated to only 17,300 years ago. This Cro-Magnon’s cave painting was quite probably a projection from the visual memory of the artist onto the wall of his cave. Like Picasso, he simply traced onto the wall his mentally projected, remembered images. In effect, this is not just a photo of a wall inside a cave. It is a snapshot taken from the inside of the artist’s head, from just his behind his eyes. Notice the edginess of the drawing, the emphasis on high spatial frequencies.
There are fascinating cave and rock paintings in Australia. Noted here at the excellent Bradshaw Foundation site are two in particular — one showing voyagers in a boat, the other a queue of 26 or more deer.
 The lined up deer are especially intriguing because in Australia there were no deer. The painting must depict a literal memory brought by the artist from Borneo, or a folk memory. The deer are lined up as though along the curved edge of a crevice, and there is even a sense of perspective achieved by grading the sizes of the beasts. There is another way to look at the picture, possibly trivial, which is to observe that an insistence on the linear ordering of objects is sometimes viewed as a characteristic of autism.
The lined up deer are especially intriguing because in Australia there were no deer. The painting must depict a literal memory brought by the artist from Borneo, or a folk memory. The deer are lined up as though along the curved edge of a crevice, and there is even a sense of perspective achieved by grading the sizes of the beasts. There is another way to look at the picture, possibly trivial, which is to observe that an insistence on the linear ordering of objects is sometimes viewed as a characteristic of autism.
The existence of a pure photographic memory, in the popular sense, has never been rigorously proved, although Stephen Wiltshire certainly seems to have one.
It makes sense that photographic memory, if indeed it exists today, is extremely rare. It almost seems as though we blabbed it away — as though anyone who can talk has inhibited or subtracted from (or set up a conflict with) his or her innate ability to think in pictures. But children who are pre-verbal might in fact have a purely eidetic visual memory.
Jurassic park, Dolly, artificial life, newborn mammoths, etc.
The Denisovan girl is vastly famous. The idea she could be reborn from the DNA of her fingertip was first presented in an inverse sense by a journalist who could not resist using the formulaic lead: “This is not Jurassic Park [scoff-scoff-scoff] but ….”
Jurassic Park was a novel and 1993 movie conceived by Michael Crichton in which dinosaurs were recreated – re-hatched — from preserved samples of dinosaur DNA.
From Nature and Science the Denisovan girl’s story has flowed into major popular science media and sites, including Wired’s excellent science section, the National Geographic, the BBC, the Huffington Post and many newspapers. Science’s spectators and science fiction enthusiasts are vocal on the internet.
The Denisovan child’s clonability is simply assumed by most internet letter writers and casual commentors.
The technology of rebirth acquired credibility from Jurassic Park, from press releases in 2010 announcing the creation of artificial life, and from readily publicized efforts (more press releases) to engender, from the DNA of cells to be sought in frozen mammoth carcasses, a baby wooly mammoth. Dolly, the many mammalian clones that have succeeded her, and the cloning of a mouse from cells frozen for 15 years – all make it seem, to a watching world, that the rebirth of an extinct lifeform is possible or just around the corner.
This is actually the second go-round on cloning an archaic human. The first discussion came with the (low coverage) sequencing of a Neanderthal.
In Lone Survivors: How we came to be the only humans on earth
the distinguished paleoanthropologist Chris Stringer asks:
“….should we reverse the process of extinction and attempt to clone a Neanderthal from its newly reconstructed genome?
…it would be quite wrong to resurrect long-extinct species purely to satisfy our curiousity about them, especially if they were human. Neanderthals were the products of a unique evolutionary history in eurasia that lasted for several hundred thousand years, but they are gone, along with the world in which they evolved, and we should let them rest in peace.”
The extinct Denisovan girl has been swept into this what-if discussion with great enthusiasm. For example on the Huffington Post, one letter writer pointed out that since this little girl is not a human, technically, her animal nature might legally exempt her from the patchwork of rules and laws that forbid human cloning.
Actually, the Denisovan girl cannot be cloned. No cells. Her DNA is shattered. All we have is her code, which was carefully pieced back together inside a computer. It is far easier to re-assemble a fragmented genome with algorithms than with biochemistry. The Denisovan girl’s genome resides on digital memory media — not in chromatin.
Some assembly required:
The human genome comprises 3 billion base pairs. This is out of reach. The current world record for genome synthesis is about 4 million base pairs. This is 1/750th of the length of a human genome.
In the TV movie of this story we would simply push a button and synthesize from the Denisovan girl’s known DNA sequence a molecular copy of her genome, using a computer to instruct an automatic DNA synthesizer.
Contemporary automatic synthesizers, however, cannot manufacture long stretches of DNA. They make oligonucleotides. “Oligos” are short DNA polymers of 20 to 50 bases. As the polymer gets longer errors inherent in the automated chemical synthesis of DNA grow problematical. The error rate is about 1 base in 100. A practical upper limit on polymer length is in most cases about 200 bases. The longer the polymer the more likely the errors, and thus, the lower the yield of accurate copies.
Traditionally, long DNA polymers were constructed by assembling short strands step by step, sequentially adding the correct short fragments to an ever lengthening chain.
In the PNAS for December 23, 2008 Gibson, Hutchinson, Venter et al reported a new technique that had been used to assemble a long DNA polymer from 25 short DNA fragments in a single step. They created the original fragments with synthesizers, then assembled them in yeast to produce an artificial genome. The enzymatic machinery that does this work normally repairs yeast DNA. But from a practical point of view, it is as though yeast had a built-in algorithm for ordering and assembling fragments of DNA. The first genome they produced with just one assembly step in yeast was that of mycoplasm genitalia, which is about 590 kilobases long.
In July, 2010, Venter’s group reported that they had created (though in more than one step) an even longer artificial genome. It was that of Mycoplasma mycoides, which is 1.08 million base pairs in length. This artificial genome was introduced into a donor cell, where the synthetic DNA took over. The transfer succeeded completely and the cell was self replicating. This was the milestone headlined as the creation of “artificial life.” All of the cell’s DNA was artificial in the sense that it had been chemically synthesized. Nine years later, an E. coli cell was fitted with a wholly synthetic genome about 4 million base pairs long.
Would this technique help recreate the Denisovan girl’s genome of 3 billion base pairs? No.
The limitation on genome synthesis is its marginal accuracy. If you scaled up the process today you would also, necessarily, scale up the number of mistakes it writes into the genome – departures from the digitized blueprint. Some errors are trivial or silent and some could be catastrophic.
The problem ultimately comes back to the automated chemical oligonucleotide synthesizers at the front end of the process. They are limited to making oligos because of the rate at which they make mistakes.
Automated chemical DNA synthesizers have been around since the 1970s. The sister technology of DNA sequencing machines has progressed dramatically through several generations by running chemistries in parallel. It is now possible to sequence a long genome very rapidly and economically. You could have your own genome sequenced for less than $2000. But it is still only possible to synthesize a relatively short genome like those of the mycoplasms or E. coli. And it is expensive.
An entirely new DNA synthetic process, using enzymes perhaps, might make it possible to create de novo a very long DNA polymer faithful to a human genome from a digital database. But not tomorrow morning.
 Photo by Dmitry Artyukhov. Mouth of the Denisova cave.
Photo by Dmitry Artyukhov. Mouth of the Denisova cave.
Is there another way?
Many biochemical interventions, including mammalian cloning, rely upon cellular machinery that is already in place in a host cell. This borrowed biochemical watchworks is not completely understood nor necessarily even known to us.
For the Denisovan girl, none of this machinery exists anymore. There survives today no Denisovan cell. What have survived are long stretches of Denisovan-like DNA in the genomes of Melanesians, including Papuans and Aborigines of Australia. About 6% of aboriginal DNA is very like that of the Denisovan girl.
Since no Denisovan cell is at hand, and no Denisovan genome can be accurately synthesized with contemporary technology — one might seek to edit into Denisovan form a modern human genome from a living cell.
This would require making 112,000 single nucleotide changes in the exactly right positions, plus 9500 insertions and deletions. This would get you close, within some tolerance, to the recorded genome of the Denisovan girl. From this point you might work toward reproducing her.
So the Denisovan girl might walk the earth once again but if it turned out she had the ability to talk, she would have nothing to tell us about her first childhood in the Denisova cave 80,000 years ago.
She would not remember her first life. That information was stored in some way in her head, not in her finger. As for her second life, to be lived among us charming, untroubled modern humans, it would be miserable would it not? She would probably grow up near a university and she would lead a life among scientists, an examined life, a specimen’s life. Alone on the planet.
Nevertheless. she has come trekking down to us across the span of eighty thousand years. It is unimaginable that she should now be left waiting indefinitely, stored in a database. Let’s guess that a century from now, which is no time at all for this little girl, biologists will know in detail how to engineer her renaissance.
To what end?
An exploit. Biology’s moonshot. To use technology to defy time and death.
But scientifically?
The Denisovan girl has given us a new genetic baseline or datum line. It would help us to see her in person. The hope would be that we could learn from her phenotype and her genome how modern humans are different, biochemically, from archaic humans.
Evolution is not an upward path leading to ourselves. In terms of language genes and skills and language-based thinking, we excel. In terms of visual or picture-based thinking, I suspect we have long since plummeted below the Denisovan baseline. A facility for language is useful but we may have paid for it with vastly diminished visual gifts. So it isn’t a question of how far we modern humans have come. It is also a question of what we have lost, jettisoned or suppressed.